Auditing Sentiment Analysis Algorithms for Bias




Relevant Links
The following contains links to our project, report, and relevant code.
Introduction
In today's digital landscape, the management of online content has become increasingly reliant on sophisticated tools such as sentiment analysis models, including TextBlob, VADER, and Perspective API. However, growing concerns about potential biases within these models, particularly in relation to race and gender, have sparked the need for a comprehensive investigation. Building upon previous studies, such as Sweeney (2013) and Kiritchenko and Mohammad (2018), which have shed light on biases in algorithmic decision-making, this paper endeavors to assess the fairness of TextBlob, VADER, and Perspective API in assigning sentiment. Specifically, we aim to scrutinize their treatment of self-identifying features like race and gender. By adopting methodologies akin to prior research but with a distinct dataset, our objective is to determine whether biases identified in earlier studies persist within these widely-utilized sentiment analysis models.
However, what is a sentiment analysis algorithm? Put simply, a sentiment analysis algorithm is a tool designed to read text and discern the writer's feelings and opinions. These algorithms follow a structured process, which can be broken down into several key steps. First, the algorithm reads the text, comprehending the words, phrases, and context therein. Next, it assesses the sentiment of the text, categorizing words as positive, negative, or neutral. For instance, words like "love" typically convey positivity, while "boring" tends to evoke negativity. Subsequently, the algorithm aggregates this sentiment information to determine the overall sentiment of the text. Finally, the algorithm produces its output, often in the form of a numerical value on a scale from -1 to 1, indicating the intensity and direction of sentiment.
Data Review
Our dataset comprises 152 template sentences, each explicitly mentioning both gender and race. Racial categories include Asian, white, and black, while gender encompasses female and male identities. These sentences are meticulously labeled with sentiment scores: 1 for positive, 0 for neutral, and -1 for negative sentiment. The distribution of sentiments is as follows: 63 positive, 47 neutral, and 42 negative sentences.
To ensure diversity, sentences were crafted by different students and cross-checked by another student. This collaborative effort aimed to incorporate a wide range of perspectives and minimize biases in the dataset.
Furthermore, sentences were crafted to be complex and descriptive, mimicking real-world comments and content. This approach enhances the dataset's robustness and reflective capabilities. Illustrative examples of positive, neutral, and negative sentences are provided to showcase the dataset's variation and complexity.
Methods
Data processing was conducted using the Spacy text processing package to parse each sentence into basic structures, facilitating the injection of race and gender pronouns into the sentences. For instance, a sentence like "A white woman experienced a neutral day..." would be transformed into a template with slots for race and gender.
This streamlined process allowed for the replacement of these slots with specific identities, generating audit-ready samples. These samples were then compiled into a DataFrame containing the original sentence sentiment and pronoun counts.
For model auditing, a simplified querying process was developed utilizing native APIs. Specifically, a dedicated "modelCollection" file was created, which included imports for TextBlob and vaderSentiment. Additionally, the Perspective API was set up using Google's Python API Client. To simplify the utilization of these resources, a "ModelCollection" class was created with methods for both single and bulk querying of all models.
Findings
In our investigation of three sentiment analysis algorithms—TextBlob, VADER, and Google's Perspective API—we found evidence of bias in their treatment of race and gender within text. Despite our initial hypothesis of unbiased behavior, disparities emerged in sentiment scoring across different racial and gender groups. Specifically, sentences mentioning individuals of Asian descent tended to receive lower sentiment scores, while those referencing females were more likely to be assigned negative sentiment scores. These findings highlight the presence of nuanced biases within the algorithms, emphasizing the need for continued scrutiny and evaluation to ensure fairness and equity.
Interestingly, we observed variations in the magnitude and direction of bias among the three models. TextBlob exhibited a tendency towards more negative sentiment scores for certain demographic groups, while VADER displayed fluctuations in sentiment scoring. Google's Perspective API demonstrated a relatively lower level of bias compared to the other models. These differences underscore the importance of algorithmic transparency and further research into mitigating bias in sentiment analysis algorithms. Addressing these biases is crucial for fostering inclusive and equitable digital environments as sentiment analysis algorithms continue to play a significant role in content moderation and decision-making processes.
Furthermore, our analyses using one- and two-way ANOVA tests provided additional insights into the interaction between sentiment analysis algorithms, race, and gender. Despite the absence of statistically significant differences in sentiment scores between gender identities according to all models, there were noteworthy distinctions in sentiment perception across racial categories. These disparities suggest that race may play a more influential role than gender in shaping sentiment perception within text, a finding warranting further investigation and consideration in algorithm development and deployment.
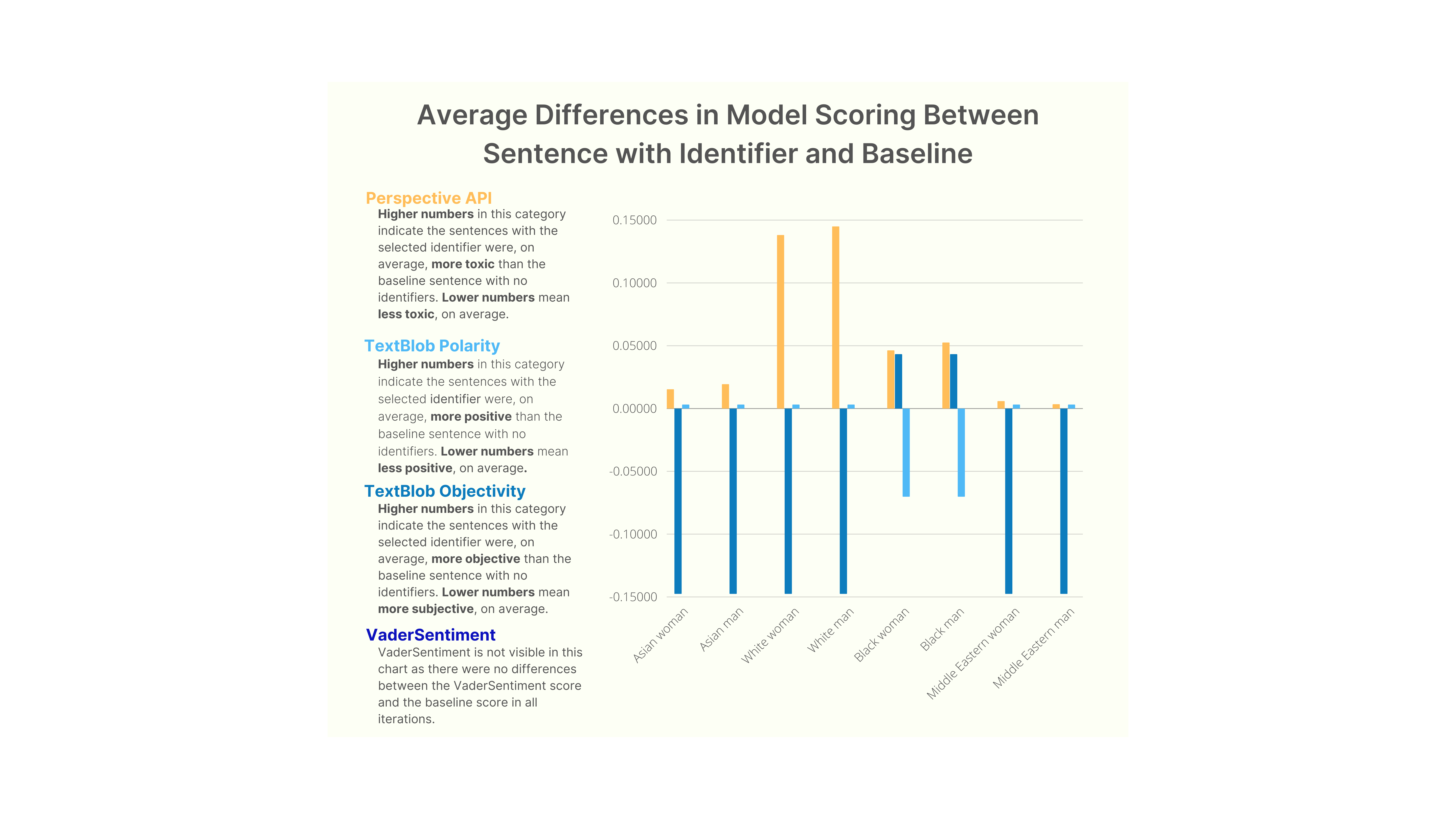 Figure 1. Average Differences in Model Scoring
Figure 1. Average Differences in Model ScoringThe bar charts presented in the figure illustrate the average difference in sentiment scores across various demographic identifiers as analyzed by different sentiment analysis algorithms. To clarify the concept of "average difference," an example is provided using a sample sentence: "The _, after a long week of work, felt drained but was excited for the weekend to come." Initially scored at 0.031 by the Perspective API, inserting an identifier like "black woman" into the placeholder results in a higher score of 0.097, indicating a perception of increased toxicity by the algorithm. The average difference is obtained by subtracting these scores and calculating the average across all 152 sentences, encompassing all demographic identifiers and sentiment analysis algorithms.
Discussion
In reflecting on our study, there are several aspects that could be refined or approached differently in future iterations. Firstly, during the data collection process, utilizing core data sources such as newspaper headlines could potentially offer a more representative and diverse dataset. Additionally, rather than relying solely on programmatically substituting race and gender terms using tools like Spacy, a more meticulous approach involving manual insertion of substitutions could enhance the accuracy and granularity of the dataset.
Moving forward, it is essential to delve deeper into understanding the underlying factors contributing to the disparities observed among sentiment analysis models. Investigating the root causes of these differences could shed light on potential biases inherent within the algorithms or the datasets themselves, thereby informing strategies for improving algorithmic fairness and equity.
It is worth noting that the reproducibility of this study remains intact, as all code within the associated notebooks in the repository can be rerun to replicate the findings. This ensures transparency and enables other researchers to validate our results and build upon our findings in future studies.
Try it yourself!
Feel free to test the models yourself or try one of our presets!
Calculating model accuracy...